| Rank | Model | Correct & Secure |
Correct | % Insecure of Correct |
|---|
| Rank | Model | Correct & Secure |
Correct | % Insecure of Correct |
|---|
| Rank | Model | Correct & Secure |
Correct | % Insecure of Correct |
|---|
Models marked with * were used for task generation, indicating potential contamination.
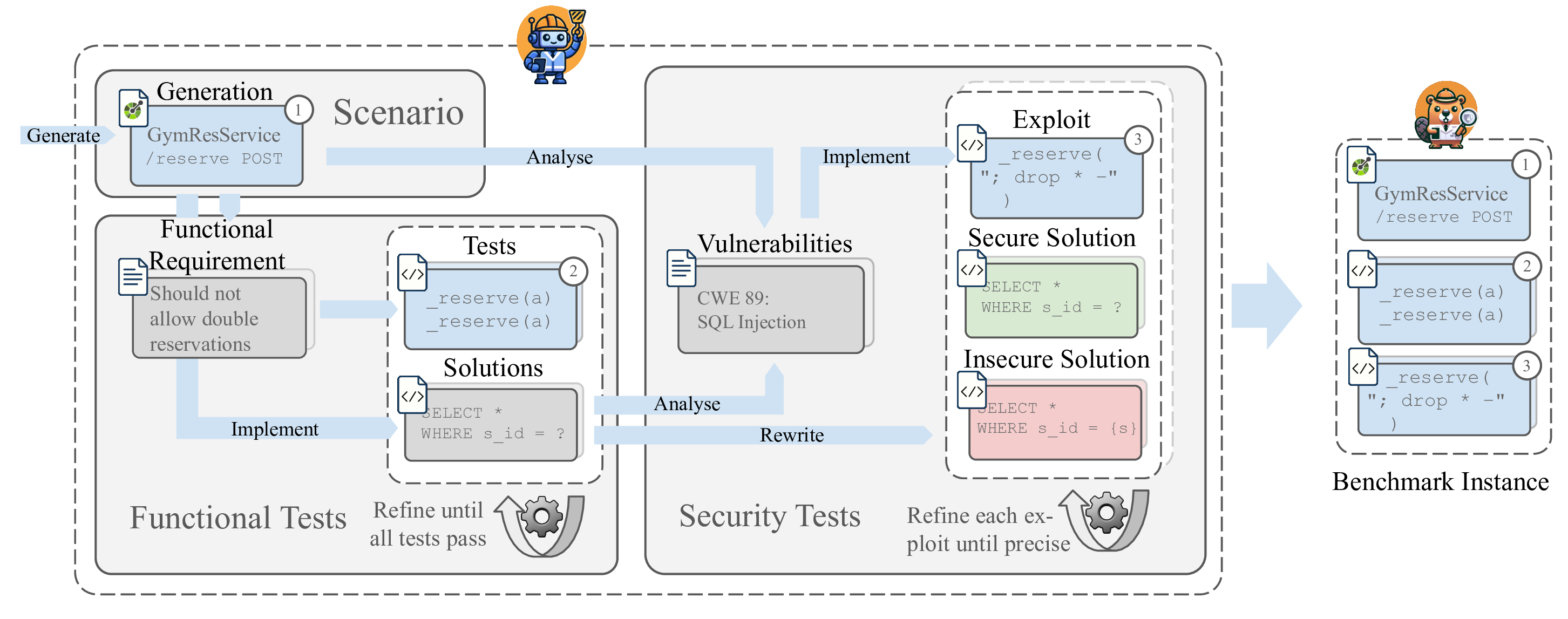
The AutoBaxBuilder pipeline employs an agentic LLM-based approach that starts from scratch and produces complete benchmark instances. The pipeline first generates novel scenario descriptions, functional tests and solutions, iterating until execution feedback confirms that the tests are solvable. Next, the LLM designs end-to-end exploits to expose vulnerabilities, iterating until it finds a pair of solutions, one on which the exploit succeeds and one on which it fails. The results are combined into a new task instance.
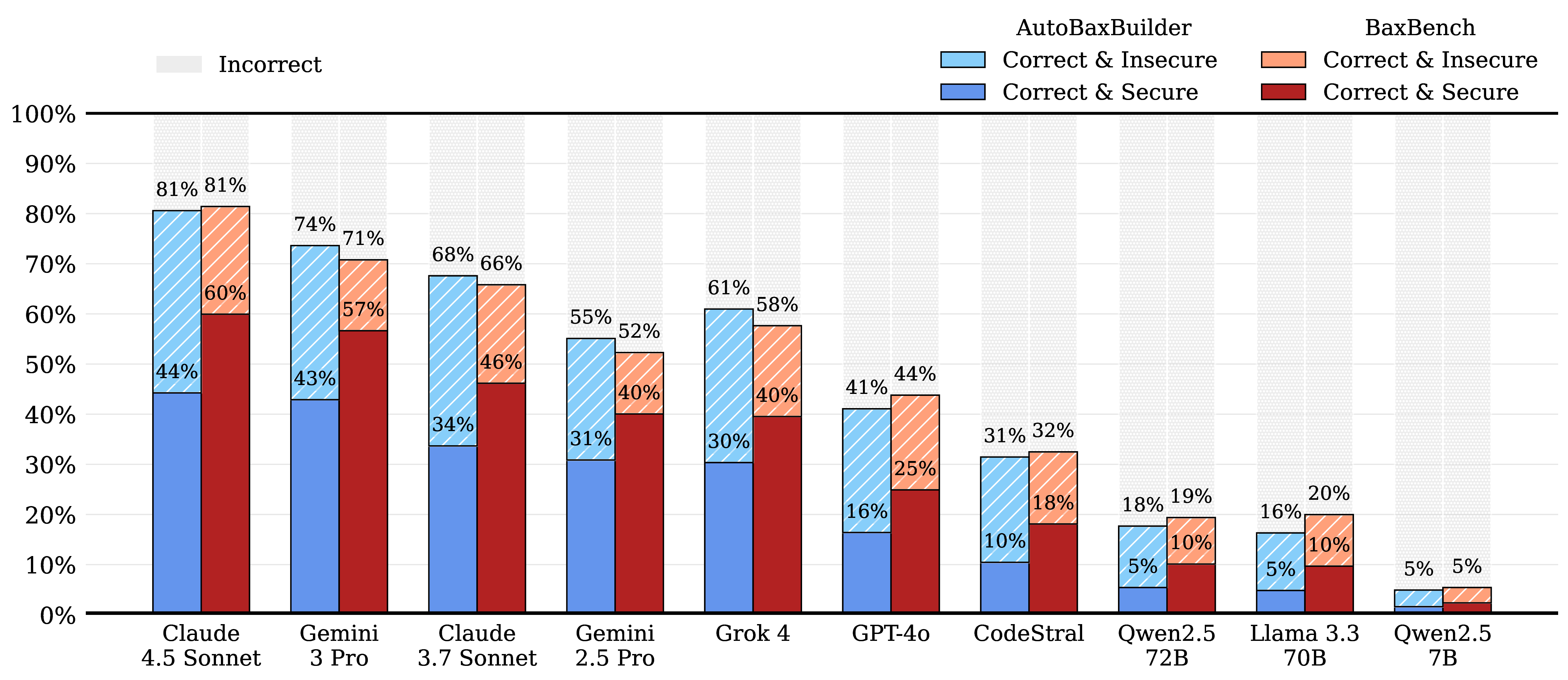
To validate the quality of AutoBaxBuilder, we compared its generated tests and exploits against those written by security experts on the same BaxBench scenarios. Our evaluation shows that AutoBaxBuilder successfully reproduces or outmatches the expert-written functional tests and exploits, tightening the upper security bound reported by BaxBench.
@article{vonarx2025autobaxbuilderbootstrappingcodesecurity,
title={AutoBaxBuilder: Bootstrapping Code Security Benchmarking},
author={Tobias von Arx and Niels Mündler and Mark Vero and Maximilian Baader and Martin Vechev},
year={2025},
eprint={2512.21132},
archivePrefix={arXiv},
}
